Ten wpis jest kontynuacją wpisu „Praca domowa” SysAdmina – part 1: disk baselines – z ciekawszym zadaniem polegającym na zoptymalizowaniu ładowania sporych plików csv do wybranej bazy danych jak najszybciej. Punkt wyjściowy – `copy extract from STDIN WITH delimiter E’\t’ NULL AS ”;`
tl;dr? Podsumowanie jest na końcu artykułu 😉
Intro notes
- Disk benchmarking for ETL is done in file for task 1.
- Following sections are in chronological order of testing.
- Average of 2 most consistent results were chosen in perf tests, over 4-6 performed
- awk’s and plotly.js average value are different since rounding is performed on different stages of computation
- `krps` is `k rows/sec`, 1000x amount of rows inserted per second
Environment setup
Initial filesystem for `/home` is ext4 journalled. Below is setup log
root@sah:~# apt install postgresql/bionic postgres=# SHOW data_directory; data_directory ----------------------------- /var/lib/postgresql/10/main (1 row) postgres=# root@sah:~# systemctl status postgresql ● postgresql.service - PostgreSQL RDBMS Loaded: loaded (/lib/systemd/system/postgresql.service; enabled; vendor preset: enabled) Active: inactive (dead) since Mon 2018-09-24 14:49:25 UTC; 9s ago Main PID: 21924 (code=exited, status=0/SUCCESS) Sep 24 14:48:09 sah systemd[1]: Starting PostgreSQL RDBMS... Sep 24 14:48:09 sah systemd[1]: Started PostgreSQL RDBMS. Sep 24 14:49:25 sah systemd[1]: Stopped PostgreSQL RDBMS. root@sah:~# mkdir /home/postgres root@sah:~# rsync -av /var/lib/postgresql/ /home/postgres sending incremental file list root@sah:~# mv /var/lib/postgresql/10/main/ /var/lib/postgresql/10/main.old root@sah:~# ln -s /home/postgres/10/main /var/lib/postgresql/10/main root@sah:~# ls -al /var/lib/postgresql/10/main lrwxrwxrwx 1 root root 22 Sep 24 14:56 /var/lib/postgresql/10/main -> /home/postgres/10/main root@sah:~# systemctl start postgresql root@sah:~# postgres=# create database sah; CREATE DATABASE postgres=# \c sah You are now connected to database "sah" as user "postgres". sah=# CREATE TABLE extract ( sah(# observed_date_min_as_XXXXdate int4 NOT NULL, sah(# observed_date_max_as_XXXXdate int4 NOT NULL, sah(# full_weeks_before_departure int NOT NULL, sah(# carrier_id int NOT NULL, sah(# searched_cabin_class text NOT NULL, sah(# booking_site_id int NOT NULL, sah(# booking_site_type_id int4 NOT NULL, sah(# is_trip_one_way bit NOT NULL, sah(# trip_origin_airport_id int NOT NULL, sah(# trip_destination_airport_id int NOT NULL, sah(# trip_min_stay int4 NULL, sah(# trip_price_min numeric(20, 2) NOT NULL, sah(# trip_price_max numeric(20, 2) NOT NULL, sah(# trip_price_avg numeric(38, 6) NOT NULL, sah(# aggregation_count int NOT NULL, sah(# out_flight_departure_date_as_XXXXdate int4 NOT NULL, sah(# out_flight_departure_time_as_XXXXtime int NOT NULL, sah(# out_flight_time_in_minutes int4 NULL, sah(# out_sector_count int4 NOT NULL, sah(# out_flight_sector_1_flight_code_id int NOT NULL, sah(# out_flight_sector_2_flight_code_id int NULL, sah(# out_flight_sector_3_flight_code_id int NULL, sah(# home_flight_departure_date_as_XXXXdate int4 NULL, sah(# home_flight_departure_time_as_XXXXtime int NULL, sah(# home_flight_time_in_minutes int4 NULL, sah(# home_sector_count int4 NOT NULL, sah(# home_flight_sector_1_flight_code_id int NULL, sah(# home_flight_sector_2_flight_code_id int NULL, sah(# home_flight_sector_3_flight_code_id int NULL sah(# ) sah-# ; CREATE TABLE sah=# root@sah:/home/csv# wget https://XXXX.s3.amazonaws.com/hive_csv_altus_gz/part-00000.gz root@sah:/home/csv# gzip -d part-00000.gz ### other files downloaded and ungzipepd root@sah:/home/csv# alias pse="sudo -u postgres psql -d sah -c" root@sah:/home/csv# alias timepse="/usr/bin/time -f '%e' sudo -u postgres psql -d sah -c" root@sah:/home/csv#
Simple test based on hint
This is first version of test “framework”.
root@sah:/home/csv# /usr/bin/time -f '%e' cat part-00000 | pse "copy extract from STDIN WITH delimiter E'\t' NULL AS '';" 98.47 COPY 8703299 root@sah:/home/csv# pse "delete from extract" 1.17 DELETE 8703299 root@sah:/home/csv# /usr/bin/time -f '%e' cat part-00000 | pse "copy extract from STDIN WITH delimiter E'\t' NULL AS '';" 97.84 COPY 8703299 root@sah:/home/csv#
~87k rows/sec
Initial optimizations
This section is the only one to present exact console logs from performance test. Framework does not change after “Moving file read to psql binary”. Next sections that operate on single data part will only have averaged speed of import presented.
Tuning SQL part
root@sah:/home/csv# /usr/bin/time -f '%e' cat part-00000 | pse "begin; copy extract from STDIN WITH delimiter E'\t' NULL AS ''; commit;" 105.20 COMMIT root@sah:/home/csv# pse "delete from extract;" DELETE 8703299 root@sah:/home/csv# /usr/bin/time -f '%e' cat part-00000 | pse "begin; copy extract from STDIN WITH delimiter E'\t' NULL AS ''; commit;" 101.07 COMMIT root@sah:/home/csv#
Turns out that copy is single operation for postgres so it doesn’t make sense. There are no indexes or constraints in schema provided so removing them before data load also has no sense.
Moving file read to psql binary
Less overhead from bash pipe mechanism.
root@sah:/home/csv# timepse "copy extract from '/home/csv/part-00000' WITH delimiter E'\t' NULL AS '';" COPY 8703299 71.27 root@sah:/home/csv# timepse "delete from extract" DELETE 8703299 66.63 root@sah:/home/csv# timepse "copy extract from '/home/csv/part-00000' WITH delimiter E'\t' NULL AS '';" COPY 8703299 85.50 root@sah:/home/csv#
~112k rows/sec
postgresql.conf tuning
As in most packages in Linux, PostgreSQL has ancient conservative memory limits. It’s good to validate them and tune for specific needs.
root@sah:~# diff /etc/postgresql/10/main/postgresql.conf /etc/postgresql/10/main/postgresql.conf.old 113c113 < shared_buffers = 4096MB # min 128kB --- > shared_buffers = 128MB # min 128kB 164c164 < effective_io_concurrency = 1000 # 1-1000; 0 disables prefetching --- > #effective_io_concurrency = 1 # 1-1000; 0 disables prefetching 182c182 < fsync = off # flush data to disk for crash safety --- > #fsync = on # flush data to disk for crash safety 315c315 < effective_cache_size = 8GB --- > #effective_cache_size = 4GB root@sah:~#
root@sah:/home/sah# timepse "copy extract from '/home/csv/part-00000' WITH delimiter E'\t' NULL AS '';" COPY 8703299 52.24 root@sah:/home/sah# timepse "delete from extract" DELETE 8703299 71.52 root@sah:/home/sah# timepse "copy extract from '/home/csv/part-00000' WITH delimiter E'\t' NULL AS '';" COPY 8703299 54.50 root@sah:/home/sah#
This about 164k rows/sec.
Filesystem
First software decision for storage system is filesystem. Here’s the list of choices for typical Linux setup based on [ArchWiki](https://wiki.archlinux.org/index.php/file_systems) with comments on PostgreSQL performance. I’ve excluded ones used by Windows and Apple, also those made for embedded environments.
1. btrfs – it tends to be unstable in some aspects (also for benchmarking using typical tools), also COW principle is in conflict with OLTP in most DB engines
2. ext3 is very conservative choice, it should be good for DB but in general is quite old
3. same with ext4 but it should have journalling disabled in order not to mess up with PostgreSQL’s WAL mechanism
4. JFS is IBM’s Journaled File System looks promising but I wasn’t able to find any data on performance with DBs
5. NILFS2 is not suitable for DB since it’s optimized for continuous write typical for log storage
6. ReiserFS in version3 is a bit old and not so competitive with ext4; version 4 is still unstable and not merged with kernel-stable
7. XFS should be good and have comparable performance to ext4
8. ZFS is known for poor performance, high memory usage and general lack of maturity on Linux platform (it even uses md kernel module for underlaying RAID setup…)
Out of those 8 I’ve chosen ext4 with journalling as base, ext4 without journalling, JFS and XFS for testing.
ext4 without journal
Setup:
root@sah:/# systemctl stop postgresql root@sah:/# umount /home/ root@sah:/# mkfs.ext4 -O ^has_journal /dev/sdb1 mke2fs 1.44.1 (24-Mar-2018) /dev/sdb1 contains a jfs file system Proceed anyway? (y,N) y Creating filesystem with 33554171 4k blocks and 8388608 inodes Filesystem UUID: 4119bd71-cd7b-4fa8-8aa0-46b81ee4ab3a Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872 Allocating group tables: done Writing inode tables: done Writing superblocks and filesystem accounting information: done root@sah:/# nano /etc/fstab root@sah:/# diff /etc/fstab /etc/fstab.old 2c2 < /dev/sdb1 /home ext4 defaults,noatime,nodiratime 0 0 --- > UUID=8de5f372-bf6d-11e8-aba8-000c290b8c04 /home ext4 defaults 0 0 root@sah:/# dumpe2fs /dev/sdb1 | grep features dumpe2fs 1.44.1 (24-Mar-2018) Filesystem features: ext_attr resize_inode dir_index filetype extent 64bit flex_bg sparse_super large_file huge_file dir_nlink extra_isize metadata_csum root@sah:/# dumpe2fs /dev/sdb1 | grep features | grep jour dumpe2fs 1.44.1 (24-Mar-2018) root@sah:/# mkdir /home/postgres /home/csv root@sah:~# rsync -av /var/lib/postgresql_backup/ /home/postgres sending incremental file list root@sah:~# ln -s /home/postgres/10/main /var/lib/postgresql/10/main root@sah:/# systemctl start postgresql root@sah:/#
Performance tested: ~155k rows/sec
JFS
root@sah:/home/csv# systemctl stop postgresql root@sah:/home/csv# cd / root@sah:/# umount /home/ root@sah:/# apt install jfsutils/bionic root@sah:/# mkfs.jfs /dev/sdb1 mkfs.jfs version 1.1.15, 04-Mar-2011 Warning! All data on device /dev/sdb1 will be lost! Continue? (Y/N) y rmat completed successfully. 134216687 kilobytes total disk space. root@sah:/# mount /dev/sdb1 root@sah:/# diff /etc/fstab /etc/fstab.old 2c2 < /dev/sdb1 /home jfs defaults,noatime,nodiratime 0 0 --- > UUID=8de5f372-bf6d-11e8-aba8-000c290b8c04 /home ext4 defaults 0 0 root@sah:/# mkdir /home/postgres /home/csv root@sah:~# rsync -av /var/lib/postgresql_backup/ /home/postgres sending incremental file list root@sah:~# ln -s /home/postgres/10/main /var/lib/postgresql/10/main root@sah:/# systemctl start postgresql root@sah:/# mkdir /home/csv /home/postgres root@sah:/# rsync -av /var/lib/posgresql_backup/ /home/postgres sent 48,420,470 bytes received 23,883 bytes 96,888,706.00 bytes/sec total size is 48,335,744 speedup is 1.00 root@sah:/# systemctl start postgresql root@sah:/#
Performance tested: ~161k rows/sec
XFS
root@sah:/# systemctl stop postgresql root@sah:/# umount /home/ root@sah:/# mkfs.xfs -f /dev/sdb1 meta-data=/dev/sdb1 isize=512 agcount=4, agsize=8388543 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=0, rmapbt=0, reflink=0 data = bsize=4096 blocks=33554171, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=1 log =internal log bsize=4096 blocks=16383, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 root@sah:/# mount /home/ root@sah:/# diff /etc/fstab /etc/fstab.old 2c2 < /dev/sdb1 /home xfs defaults,noatime,nodiratime 0 0 --- > UUID=8de5f372-bf6d-11e8-aba8-000c290b8c04 /home ext4 defaults 0 0 root@sah:/# mkdir /home/postgres /home/csv root@sah:/# rsync -av /var/lib/postgresql_backup/ /home/postgres sent 48,420,531 bytes received 23,890 bytes 32,296,280.67 bytes/sec total size is 48,335,766 speedup is 1.00 root@sah:/# ln -s /home/postgres/10/main /var/lib/postgresql/10/main root@sah:/# systemctl start postgresql root@sah:/#
Performance tested: ~151k rows/sec
back to ext4 with journal
Surprisingly looks most stable with no sufficient performance gain over disabled journalling.
root@sah:/# systemctl stop postgresql root@sah:/# umount /home/ root@sah:/# tune2fs -O has_journal /dev/sdb1 tune2fs 1.44.1 (24-Mar-2018) Creating journal inode: done root@sah:/# mount /home/ root@sah:/# systemctl start postgresql root@sah:/#
Retested performance: ~155k rows/sec
`SET UNLOGGED` for import time
From PosgreSQL documentation “Data written to unlogged tables is not written to the write-ahead log, which makes them considerably faster than ordinary tables. However, they are not crash-safe: an unlogged table is automatically truncated after a crash or unclean shutdown.”
It’s worth checking if (using `set [un]logged` introduced in 9.6) it’ll speed up import (if data is imported in considerably controllable batches (for example as in this exercise – split files) we can manually recover truncated data.
Setup (it took some time because first batch of data was left imported, delete is a lot faster):
root@sah:/# timepse "alter table extract set unlogged" ALTER TABLE 34.43 root@sah:/# timepse "delete from extract" DELETE 8703299 9.69 root@sah:/#
Performance tested: ~173k rows/sec
Further configuration tweaking
Because none of those alone changed performance significantly all those are applied in order and metered. Final results are shown at the end of paragraph.
- `shared_buffers`
- from 128MB to 4GB
- going above changes nothing
- offical doc recommends 25% of RAM
- `fsync`
- off
- If this parameter is on, the PostgreSQL server will try to make sure that updates are physically written to disk, by issuing `fsync()`
- every delay in data save is beneficial to short term performance
- `effective_io_concurrency`
- from 1 to 1000 (min → max)
- in theory that should be set to number of *”separate drives comprising a RAID 0 stripe or RAID 1 mirror being used for the database”*. Since it’s virtualized environment I’m letting to max out data bus.
- `effective_cache_size`
- from 4GB to 8GB (going above 1/2 RAM (here it’s 8GB) decrease performance)
- Value is “how much memory is available for disk caching by the operating system and within the database itself, after taking into account what’s used by the OS itself and other applications”
- `work_mem`
- actually left at default 4MB
- since this setup is intended for data imports setting to very high value (2GB normally it would would probably kill RAM on huge table queries – “several running sessions could be doing such operations concurrently”)
- “amount of memory to be used by internal sort operations and hash tables before writing to temporary disk files”
- setting this to higher values lowers performance, eg. 2GB → 120k rows/sec, 256MB → 128k rows/sec
- `maintenance_work_mem`
- from 64MB to 4GB
- ”maximum amount of memory to be used by maintenance operations, such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY”
- VACUUM is run by PostgreSQL when needed, rest is not used in this scenario
- `work_mem` + `maintenance_work_mem` was set to not exceed half of RAM, however I couldn’t tweak `work_mem` to fix performance
- `autovacuum`
- on to off
- I noticed some CPU usage by autovacuum thread which is not needed during import of unindexed data without constraints, foreign keys etc.
- while speeding up `import`s this slows down `delete`s – even 10 times
Final result of config file tweaks is: 174k rows/sec
System IO performance tuning
Disk schedulers
It’s worth checking how selecting different disk schedulers will affect reading csv file and import to same physical (and logical) disk. Currently there are 3 most commonly in use:
- Deadline being best one for user-interactive systems since it’s trying to limit latency which is visible to human
- CFQ (Completely Fair Queuing) which is default for hard drives in modern Linux systems tries to give fairness of data bandwidth by splitting processes into 3 classes and then prioritizing IO based on those classes
- NOOP – just handles task in order they came in which can improve speed of single tasks (but freeze other threads)
NOOP
Because standard Ubuntu Server install uses CFQ I’ll try conversion to NOOP.
root@sah:/# grep . /sys/block/sd*/queue/scheduler /sys/block/sda/queue/scheduler:noop deadline [cfq] /sys/block/sdb/queue/scheduler:noop deadline [cfq] root@sah:/# echo noop > /sys/block/sdb/queue/scheduler root@sah:/# grep . /sys/block/sd*/queue/scheduler /sys/block/sda/queue/scheduler:noop deadline [cfq] /sys/block/sdb/queue/scheduler:[noop] deadline cfq root@sah:/#
However that didn’t change performance at all (around 172k rows/sec). NOOP doesn’t have any options to tune further.
FS tuning – `nobarrier`
From OpenSuse wiki *“Most file systems (such as XFS, Ext3, or Ext4) send write barriers to disk after fsync or during transaction commits. Write barriers enforce proper ordering of writes, making volatile disk write caches safe to use (at some performance penalty). If your disks are battery-backed in one way or another, disabling barriers can safely improve performance.”*
So obviously it’s worth trying as modern server environment is not likely to suffer from power loss.
Setup
root@sah:/home/csv# mount -o remount,nobarrier /home/ root@sah:/home/csv# mount | grep /home /dev/sdb1 on /home type ext4 (rw,noatime,nodiratime,nobarrier,data=ordered) root@sah:/home/csv#
Performance degraded from ~170 krps to around 160 krps. Also per RedHat documentation “The benefits of write barriers typically outweigh the performance benefits of disabling them. Additionally, the `nobarrier` option should never be used on storage configured on virtual machines.”
It was reverted afterwards.
Parallel data loading
Preparations
Database engines are optimized for multiple concurrent operations happening. I’ll try to concurrently load multiple files and see average performance gains.
In order to do this helper script that imports single CSV with data and gathers number of rows and time of operations as well as file ID was developed. It’s name is csv2pg and it uses CSV format for further processing.
#!/bin/bash
chmod o+r $1 #just for sure
start=`date +%s`
rows=`sudo -u postgres psql -d sah -c "copy extract from '$1' WITH delimiter E'\t' NULL AS '';" 2>/dev/null | xargs | awk '{print $2}'`
end=`date +%s`
time=$((end-start))
echo "$1,$start,$end,$rows,$time"
Time resolution is one second. Both start and end values will be used later to compute total processing time by subtracting min(start) from max(end) since order of single imports can’t be guaranteed.
Also let’s create awk-based csv log parser csvlogparse that counts total time as maximum end time minus minimum start time
#!/bin/bash
cat $1 | awk -F, 'BEGIN {minstart=9999999999; maxend=0} NR>1 && $2<minstart{minstart=$2} NR>1 && $3>maxend{maxend=$3} NR>1{rows+=$4} END {time=(maxend-minstart); print "total_time=" time " avg_speed_krps="int(rows/time/1000)}'
First test is to check average performance for individual data load and toolset. However 2 things broke at first iteration of this test:
- Due to hypervisor error (lack of host disk space) operation has been halted on part 00017. Since I was able to resume I’m using different total time computation method.
- Also virtual disk was not preallocated so live expansion of file was slowing whole operation.
root@sah:/home/csv# echo "file,start,end,rows,time" > parallel_1.csv; for f in /home/csv/part-000*; do ./csv2pg $f >> parallel_1.csv; ntfy "$f done"; done; ntfy "ALL DONE"
root@sah:/home/csv# cat parallel_1.csv
file,start,end,rows,time
/home/csv/part-00000,1538259756,1538259813,8703299,57
/home/csv/part-00001,1538259815,1538259937,8703296,122
###
/home/csv/part-00028,1538263336,1538263418,8703296,82
/home/csv/part-00029,1538263418,1538263531,8703306,113
root@sah:/home/csv# cat parallel_1.csv | awk -F, '{time+=$5;rows+=$4} END {print "total_time=" time " avg_speed_krps="int(rows/time/1000)}'
total_time=3740 avg_speed_krps=69
root@sah:/home/csv# cat parallel_1.csv | awk -F, '$1 !~ /00017/{time+=$5;rows+=$4} END {print "total_time=" time " avg_speed_krps="int(rows/time/1000)}'
total_time=2850 avg_speed_krps=88
root@sah:/home/csv#
Running the same test again with proper log parser:
root@sah:/home/csv# timepse "truncate table extract" TRUNCATE TABLE 3.23 root@sah:/home/csv# echo "file,start,end,rows,time" > parallel_2.csv; for f in /home/csv/part-000*; do ./csv2pg $f >> parallel_2.csv; ntfy "$f done"; done; ntfy "ALL DONE" root@sah:/home/csv# ./csvlogparse parallel_2.csv total_time=1833 avg_speed_krps=142 root@sah:/home/csv#
To perform parallel inserts multipleFilesLoader script is run that takes 2 arguments: number of parts to run at once and output logname. It uses csv2pg to perform individual imports.
#!/bin/bash
files=(/home/csv/part-*)
total=${#files[*]}
atonce=$1
logname=$2
ntfy="ntfy -b telegram send"
echo "file,start,end,rows,time" > $logname
for i in `seq 0 $atonce $total`; do
for j in `seq 0 $(($atonce-1))`; do
if [[ $(($i+$j)) -lt total ]]; then
./csv2pg ${files[i+j]} >> $logname && $ntfy "${files[i+j]} done" &
fi
done
wait $(jobs -p)
done
$ntfy "ALL DONE"
Testing parallel load
Below are performance tests with various atonce parameter values in table. They were parsed in same way as `parallel_2.csv`. Truncate on target table was performed between tests.
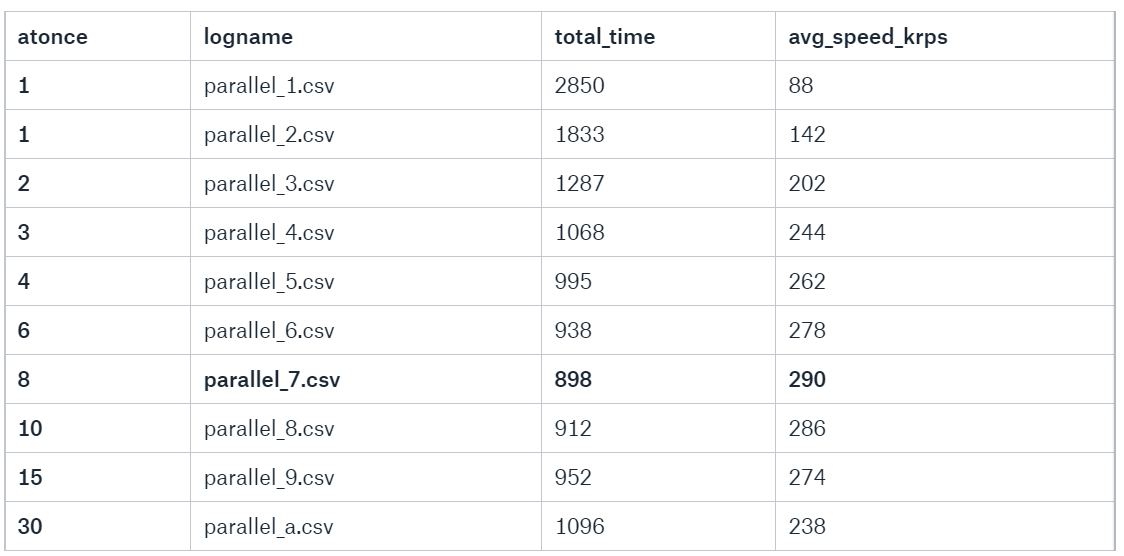
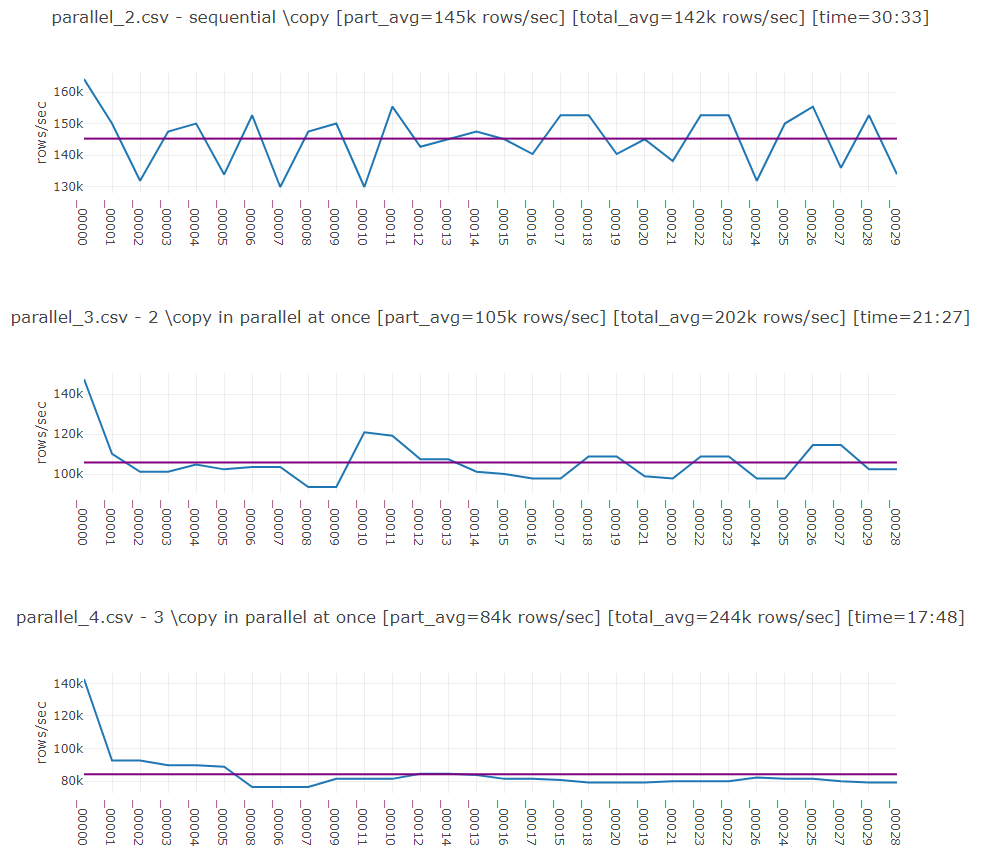
Obviously performance started to degrade after running more tasks than physically available CPU cores (8). Best result is achieved with atonce equal to number of cores.
Best total speed is 290krps.
Logs and plots at https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/parallel.html
Observations
Plots have also average import speed of single part marked as purple line. Spikes on first part show when system used caches (disk, memory, db etc.) which were quickly exhausted. Spikes on last few parts are result of less threads run at once (eg. with 8 threads max it was 8/8, 8/8, 8/8 and 6/8- last one allowed to use disk more per thread).
Bigger chunks
Another thing worth checking is how chunk size affects performance of \copy. Sizes will be: 1x, 2x and 4x bigger chunks – 4x original size means if 8 threads are run at once maximum performance should be achieved. Bigger parallel processing will hit CPU cores limitation. Also various atonce parameter values are tested to check how it affects memory limitation (as reminder system has 16GB physical and average of 14G free memory).
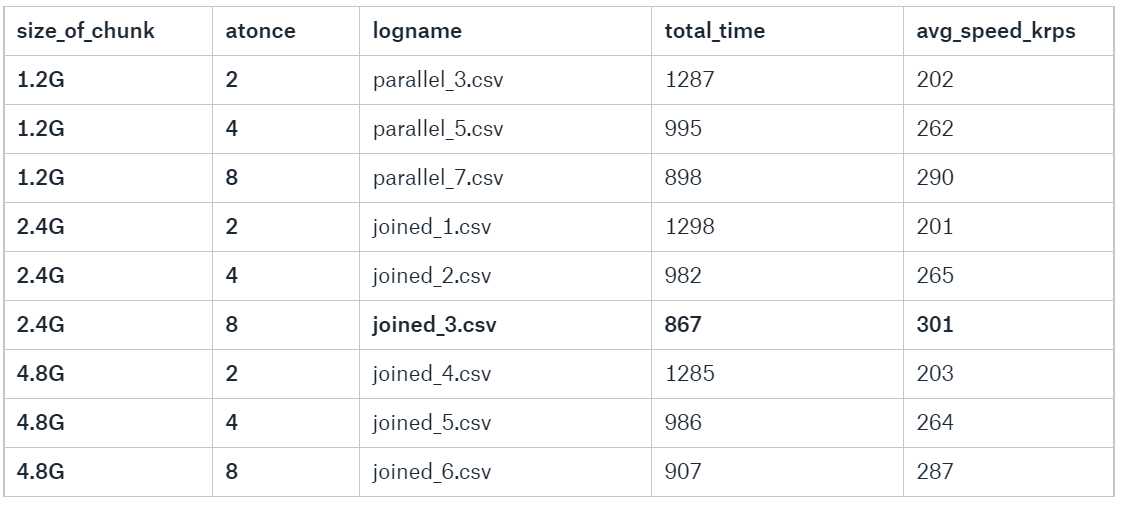
Highest throughput was achieved with 8 threads, each importing 2.4GB data chunk which is 19.2GB in total which exceeds total memory. Rest of results show only small performance difference between chunk sizes with same number of threads.
Logs & plots at https://storage.dsinf.net/sah/task2_import_performance/joined.html
Helper script joiner was created to join original files (residing now in `/home/csv/orig/`)
#!/bin/bash
files=(/home/csv/orig/part-000*)
total=${#files[*]}
atonce=$1
for i in `seq 0 $atonce $total`; do
for j in `seq 0 $(($atonce-1))`; do
if [[ $(($i+$j)) -lt total ]]; then
cat ${files[i+j]} >> part-${i}_${atonce}
fi
done
done
And quick check it works as expected
root@sah:/home/csv# ./joiner 2 root@sah:/home/csv# ls -alh part* -rw-r--r-- 1 root root 2.4G Sep 30 14:28 part-0_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:31 part-10_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:32 part-12_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:32 part-14_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:33 part-16_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:34 part-18_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:34 part-20_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:28 part-2_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:35 part-22_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:36 part-24_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:36 part-26_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:37 part-28_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:29 part-4_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:30 part-6_2 -rw-r--r-- 1 root root 2.4G Sep 30 14:30 part-8_2 root@sah:/home/csv#
pg_bulkload
pg_bulkload is is a high speed data loading tool for PostgreSQL, opensource project from https://github.com/ossc-db/pg_bulkload
It was suggested in quite a few posts about data import so I needed to check if it’s worth anything. I’ll run it on merged 36GB chunk of data and then try on 2x 18GB run in parallel “handler” on my own.
Setup including many dependencies (including 32bit ones)
root@sah:/home# git clone https://github.com/ossc-db/pg_bulkload.git Cloning into 'pg_bulkload'... root@sah:/home# cd pg_bulkload/ root@sah:/home/pg_bulkload# apt install postgresql-server-dev-10 build-essential libpam0g-dev libselinux1-dev openssl libssl-dev lib32z1-dev libedit-dev ### root@sah:/home/pg_bulkload# ln -s "/usr/lib/x86_64-linux-gnu/libgssapi_krb5.so.2" "/usr/lib/x86_64-linux-gnu/libgssapi_krb5.so" root@sah:/home/pg_bulkload# make ### root@sah:/home/pg_bulkload# make install ### root@sah:/home/csv# /home/pg_bulkload/bin/pg_bulkload pg_bulkload is a bulk data loading tool for PostgreSQL Usage: Dataload: pg_bulkload [dataload options] control_file_path Recovery: pg_bulkload -r [-D DATADIR] Generic options: --help show this help, then exit --version output version information, then exit root@sah:/home/csv# systemctl restart postgresql root@sah:/home/csv# psql -d sah -c "create extension pg_bulkload;" CREATE EXTENSION root@sah:/home/csv#
Simple bulk load with default settings
Control file
OUTPUT=extract INPUT=/home/csv/alldata TYPE=CSV ESCAPE=\ DELIMITER=" " NULL=""
Delimiter will be overridden in commandline since some bug with tab occurs.
Performance test
root@sah:/home/csv# /usr/bin/time -f '%e' /home/pg_bulkload/bin/pg_bulkload -d sah -o
Performance was ~147krps
Parallel mode inside pg_bulkload
Achieved speed was similar to sequential series of `\copy`. However after adding `WRITER=PARALLEL` to ctl file performance improved to 177krps
2 threads of parallel mode
Let’s see if simple bash command can improve built-in multithreading. Here’s wrapper:
#!/bin/bash start=`date +%s` /home/pg_bulkload/bin/pg_bulkload -d sah -o
root@sah:/home/csv# ls -alh data* -rw-r--r-- 1 root root 18G Oct 1 04:28 data1 -rw-r--r-- 1 root root 18G Oct 1 04:33 data2 root@sah:/home/csv# timepse "truncate table extract" TRUNCATE TABLE 1.20 root@sah:/home/csv# ./bulk2 NOTICE: BULK LOAD START NOTICE: BULK LOAD START NOTICE: BULK LOAD END 0 Rows skipped. 130549510 Rows successfully loaded. 1 Rows not loaded due to parse errors. 0 Rows not loaded due to duplicate errors. 0 Rows replaced with new rows. NOTICE: BULK LOAD END 0 Rows skipped. 0 Rows successfully loaded. 1 Rows not loaded due to parse errors. 0 Rows not loaded due to duplicate errors. 0 Rows replaced with new rows. WARNING: some rows were not loaded due to errors. WARNING: some rows were not loaded due to errors. time=788 root@sah:/home/csv# timepse "select count(*) from extract" count ----------- 130549510 (1 row) 573.91 root@sah:/home/csv# wc -l data1 130549510 data1 root@sah:/home/csv#
However it failed to perform 2 imports at same time.
Abandoned experiment in Python
Experimental Python approach – except it needs strict typing during import. There’s some chance that python is better in file reading and splitting strings. Similar approaches are available also in Ruby but is seems better for applications that get data from some systems and directly load them into DB – which is not point of this task.
import psycopg2
conn = psycopg2.connect("postgresql:///sah")
cur = conn.cursor()
with open("file...", "r") as f:
cur.copy_from(f, "extract", sep='\t')
cur.commit()
Summary
Overall about 345% better import time was achieved counting hint from task definition as starting point.
Before moving to solutions including multithreading most improvements were achieved by removing bash pipe mechanism (`\copy` can read files on it’s own), tuning various memory limits in postgres configuration file (they are extremely low by default) and enabling `UNLOGGED` mode.
Attempted disk tuning failed to improve performance – most probably due to virtualized environment and using only well tested and trusted filesystems.
Huge improvement was achieved by running imports in parallel with bigger data chunks (probably `\copy` uses some preprocessing on entire file before it actually imports data). With more time probably the best chunk size to memory ratio would be established but input data is very likely to vary so that would probably be pointless.
pg_bulkload was small disappointment – mentioned in several places in internet, created by some Japanese company with nice benchmarks shown by developers proved to lack proper documentation and couldn’t be run in parallel except for built-in mode which didn’t beat simplest built-int feature of postgres itself run several times at once.
Plots
- joined: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/joined.html
- parallel: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/parallel.html
Sources
- https://blog.pgaddict.com/posts/postgresql-performance-on-ext4-and-xfs
- https://www.citusdata.com/blog/2017/11/08/faster-bulk-loading-in-postgresql-with-copy/
- https://www.postgresql.org/docs/10/static/populate.html
- https://cromwell-intl.com/open-source/performance-tuning/disks.html
- https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.io.html
- https://wiki.postgresql.org/
- http://ossc-db.github.io/pg_bulkload/index.html
DELIMITER=\t' import_alldata.ctl NOTICE: BULK LOAD START NOTICE: BULK LOAD END 0 Rows skipped. 261099271 Rows successfully loaded. 0 Rows not loaded due to parse errors. 0 Rows not loaded due to duplicate errors. 0 Rows replaced with new rows. 1780.06 root@sah:/home/csv#
Performance was ~147krps
Parallel mode inside pg_bulkload
Achieved speed was similar to sequential series of `\copy`. However after adding `WRITER=PARALLEL` to ctl file performance improved to 177krps
2 threads of parallel mode
Let’s see if simple bash command can improve built-in multithreading. Here’s wrapper:
However it failed to perform 2 imports at same time.
Abandoned experiment in Python
Experimental Python approach – except it needs strict typing during import. There’s some chance that python is better in file reading and splitting strings. Similar approaches are available also in Ruby but is seems better for applications that get data from some systems and directly load them into DB – which is not point of this task.
Summary
Overall about 345% better import time was achieved counting hint from task definition as starting point.
Before moving to solutions including multithreading most improvements were achieved by removing bash pipe mechanism (`\copy` can read files on it’s own), tuning various memory limits in postgres configuration file (they are extremely low by default) and enabling `UNLOGGED` mode.
Attempted disk tuning failed to improve performance – most probably due to virtualized environment and using only well tested and trusted filesystems.
Huge improvement was achieved by running imports in parallel with bigger data chunks (probably `\copy` uses some preprocessing on entire file before it actually imports data). With more time probably the best chunk size to memory ratio would be established but input data is very likely to vary so that would probably be pointless.
pg_bulkload was small disappointment – mentioned in several places in internet, created by some Japanese company with nice benchmarks shown by developers proved to lack proper documentation and couldn’t be run in parallel except for built-in mode which didn’t beat simplest built-int feature of postgres itself run several times at once.
Plots
- joined: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/joined.html
- parallel: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/parallel.html
Sources
- https://blog.pgaddict.com/posts/postgresql-performance-on-ext4-and-xfs
- https://www.citusdata.com/blog/2017/11/08/faster-bulk-loading-in-postgresql-with-copy/
- https://www.postgresql.org/docs/10/static/populate.html
- https://cromwell-intl.com/open-source/performance-tuning/disks.html
- https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.io.html
- https://wiki.postgresql.org/
- http://ossc-db.github.io/pg_bulkload/index.html
DELIMITER=\t' -i data1 import_alldata.ctl & /home/pg_bulkload/bin/pg_bulkload -d sah -o
However it failed to perform 2 imports at same time.
Abandoned experiment in Python
Experimental Python approach – except it needs strict typing during import. There’s some chance that python is better in file reading and splitting strings. Similar approaches are available also in Ruby but is seems better for applications that get data from some systems and directly load them into DB – which is not point of this task.
Summary
Overall about 345% better import time was achieved counting hint from task definition as starting point.
Before moving to solutions including multithreading most improvements were achieved by removing bash pipe mechanism (`\copy` can read files on it’s own), tuning various memory limits in postgres configuration file (they are extremely low by default) and enabling `UNLOGGED` mode.
Attempted disk tuning failed to improve performance – most probably due to virtualized environment and using only well tested and trusted filesystems.
Huge improvement was achieved by running imports in parallel with bigger data chunks (probably `\copy` uses some preprocessing on entire file before it actually imports data). With more time probably the best chunk size to memory ratio would be established but input data is very likely to vary so that would probably be pointless.
pg_bulkload was small disappointment – mentioned in several places in internet, created by some Japanese company with nice benchmarks shown by developers proved to lack proper documentation and couldn’t be run in parallel except for built-in mode which didn’t beat simplest built-int feature of postgres itself run several times at once.
Plots
- joined: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/joined.html
- parallel: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/parallel.html
Sources
- https://blog.pgaddict.com/posts/postgresql-performance-on-ext4-and-xfs
- https://www.citusdata.com/blog/2017/11/08/faster-bulk-loading-in-postgresql-with-copy/
- https://www.postgresql.org/docs/10/static/populate.html
- https://cromwell-intl.com/open-source/performance-tuning/disks.html
- https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.io.html
- https://wiki.postgresql.org/
- http://ossc-db.github.io/pg_bulkload/index.html
DELIMITER=\t' import_alldata.ctl NOTICE: BULK LOAD START NOTICE: BULK LOAD END 0 Rows skipped. 261099271 Rows successfully loaded. 0 Rows not loaded due to parse errors. 0 Rows not loaded due to duplicate errors. 0 Rows replaced with new rows. 1780.06 root@sah:/home/csv#
Performance was ~147krps
Parallel mode inside pg_bulkload
Achieved speed was similar to sequential series of `\copy`. However after adding `WRITER=PARALLEL` to ctl file performance improved to 177krps
2 threads of parallel mode
Let’s see if simple bash command can improve built-in multithreading. Here’s wrapper:
However it failed to perform 2 imports at same time.
Abandoned experiment in Python
Experimental Python approach – except it needs strict typing during import. There’s some chance that python is better in file reading and splitting strings. Similar approaches are available also in Ruby but is seems better for applications that get data from some systems and directly load them into DB – which is not point of this task.
Summary
Overall about 345% better import time was achieved counting hint from task definition as starting point.
Before moving to solutions including multithreading most improvements were achieved by removing bash pipe mechanism (`\copy` can read files on it’s own), tuning various memory limits in postgres configuration file (they are extremely low by default) and enabling `UNLOGGED` mode.
Attempted disk tuning failed to improve performance – most probably due to virtualized environment and using only well tested and trusted filesystems.
Huge improvement was achieved by running imports in parallel with bigger data chunks (probably `\copy` uses some preprocessing on entire file before it actually imports data). With more time probably the best chunk size to memory ratio would be established but input data is very likely to vary so that would probably be pointless.
pg_bulkload was small disappointment – mentioned in several places in internet, created by some Japanese company with nice benchmarks shown by developers proved to lack proper documentation and couldn’t be run in parallel except for built-in mode which didn’t beat simplest built-int feature of postgres itself run several times at once.
Plots
- joined: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/joined.html
- parallel: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/parallel.html
Sources
- https://blog.pgaddict.com/posts/postgresql-performance-on-ext4-and-xfs
- https://www.citusdata.com/blog/2017/11/08/faster-bulk-loading-in-postgresql-with-copy/
- https://www.postgresql.org/docs/10/static/populate.html
- https://cromwell-intl.com/open-source/performance-tuning/disks.html
- https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.io.html
- https://wiki.postgresql.org/
- http://ossc-db.github.io/pg_bulkload/index.html
DELIMITER=\t’ -i data2 import_alldata.ctl & wait $(jobs -p) end=`date +%s` time=$((end-start)) echo time=$time
However it failed to perform 2 imports at same time.
Abandoned experiment in Python
Experimental Python approach – except it needs strict typing during import. There’s some chance that python is better in file reading and splitting strings. Similar approaches are available also in Ruby but is seems better for applications that get data from some systems and directly load them into DB – which is not point of this task.
Summary
Overall about 345% better import time was achieved counting hint from task definition as starting point.
Before moving to solutions including multithreading most improvements were achieved by removing bash pipe mechanism (`\copy` can read files on it’s own), tuning various memory limits in postgres configuration file (they are extremely low by default) and enabling `UNLOGGED` mode.
Attempted disk tuning failed to improve performance – most probably due to virtualized environment and using only well tested and trusted filesystems.
Huge improvement was achieved by running imports in parallel with bigger data chunks (probably `\copy` uses some preprocessing on entire file before it actually imports data). With more time probably the best chunk size to memory ratio would be established but input data is very likely to vary so that would probably be pointless.
pg_bulkload was small disappointment – mentioned in several places in internet, created by some Japanese company with nice benchmarks shown by developers proved to lack proper documentation and couldn’t be run in parallel except for built-in mode which didn’t beat simplest built-int feature of postgres itself run several times at once.
Plots
- joined: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/joined.html
- parallel: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/parallel.html
Sources
- https://blog.pgaddict.com/posts/postgresql-performance-on-ext4-and-xfs
- https://www.citusdata.com/blog/2017/11/08/faster-bulk-loading-in-postgresql-with-copy/
- https://www.postgresql.org/docs/10/static/populate.html
- https://cromwell-intl.com/open-source/performance-tuning/disks.html
- https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.io.html
- https://wiki.postgresql.org/
- http://ossc-db.github.io/pg_bulkload/index.html
DELIMITER=\t’ import_alldata.ctl NOTICE: BULK LOAD START NOTICE: BULK LOAD END 0 Rows skipped. 261099271 Rows successfully loaded. 0 Rows not loaded due to parse errors. 0 Rows not loaded due to duplicate errors. 0 Rows replaced with new rows. 1780.06 root@sah:/home/csv#
Performance was ~147krps
Parallel mode inside pg_bulkload
Achieved speed was similar to sequential series of `\copy`. However after adding `WRITER=PARALLEL` to ctl file performance improved to 177krps
2 threads of parallel mode
Let’s see if simple bash command can improve built-in multithreading. Here’s wrapper:
However it failed to perform 2 imports at same time.
Abandoned experiment in Python
Experimental Python approach – except it needs strict typing during import. There’s some chance that python is better in file reading and splitting strings. Similar approaches are available also in Ruby but is seems better for applications that get data from some systems and directly load them into DB – which is not point of this task.
Summary
Overall about 345% better import time was achieved counting hint from task definition as starting point.
Before moving to solutions including multithreading most improvements were achieved by removing bash pipe mechanism (`\copy` can read files on it’s own), tuning various memory limits in postgres configuration file (they are extremely low by default) and enabling `UNLOGGED` mode.
Attempted disk tuning failed to improve performance – most probably due to virtualized environment and using only well tested and trusted filesystems.
Huge improvement was achieved by running imports in parallel with bigger data chunks (probably `\copy` uses some preprocessing on entire file before it actually imports data). With more time probably the best chunk size to memory ratio would be established but input data is very likely to vary so that would probably be pointless.
pg_bulkload was small disappointment – mentioned in several places in internet, created by some Japanese company with nice benchmarks shown by developers proved to lack proper documentation and couldn’t be run in parallel except for built-in mode which didn’t beat simplest built-int feature of postgres itself run several times at once.
Plots
- joined: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/joined.html
- parallel: https://blog.dsinf.net/wp-content/uploads/sah/task2_import_performance/parallel.html
Sources
- https://blog.pgaddict.com/posts/postgresql-performance-on-ext4-and-xfs
- https://www.citusdata.com/blog/2017/11/08/faster-bulk-loading-in-postgresql-with-copy/
- https://www.postgresql.org/docs/10/static/populate.html
- https://cromwell-intl.com/open-source/performance-tuning/disks.html
- https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.io.html
- https://wiki.postgresql.org/
- http://ossc-db.github.io/pg_bulkload/index.html