
Prometheus to TSDB (TimeSeries DataBase, czyli po polsku mogłoby to być coś w rodzaju bazy danych szeregów czasowych) i zestaw lekkich agentów raportujących do niej, między innymi metryki zasobów systemu operacyjnego. Po więcej opisu systemu odsyłam do dokumentacji – https://prometheus.io/docs/introduction/overview/
Osobiście używam go najwięcej do kolekcjonowania zasobów kontenerów i maszyn wirtualnych, stanu serwisów oraz pewnych podstawowych statystyk o bazach danych i serwerach nginx. Do zestawu mam jeszcze alert managera, czyli usługę badającą stan danych w bazie i wypychającą powiadomienia do SquadCast (działa także z innymi systemami zarządzającymi incydentami jak PagerDuty, czy przez wtyczki także z komunikatorami internetowymi, np. Telegramem).
Dwa nietypowe narzędzia
Posiadam w kolekcji jednak dwa małe projekty, wykorzystujące przydatną funkcję podstawowego agenta Prometheusa – node exportera – collector.textfile do dość prymitywnego, ale skutecznego publikowania własnych danych. Są to Duplicati Dropbox Checker (https://github.com/danielskowronski/DuplicatiDropboxChecker) oraz Archer Connected Hosts Exporter (https://github.com/danielskowronski/ArcherConnectedHostsExporter).
Pierwszy z nich służy do monitorowania backupów tworzonych przez program Duplicati po przesłaniu ich przez agenta na Dropboxie (będąc dodatkowym zabezpieczeniem względem opisanych podstawowych testów wykonania samej binarki opisanego w innych artykule – https://blog.dsinf.net/2020/10/kopie-zapasowe-linuksowej-infrastruktury-i-nie-tylko-duplicati-oraz-jego-monitorowanie-za-pomoca-prometheusa/). Każda monitorowana ścieżka generuje jeden rekord – timestamp najnowszego pliku w danym folderze.
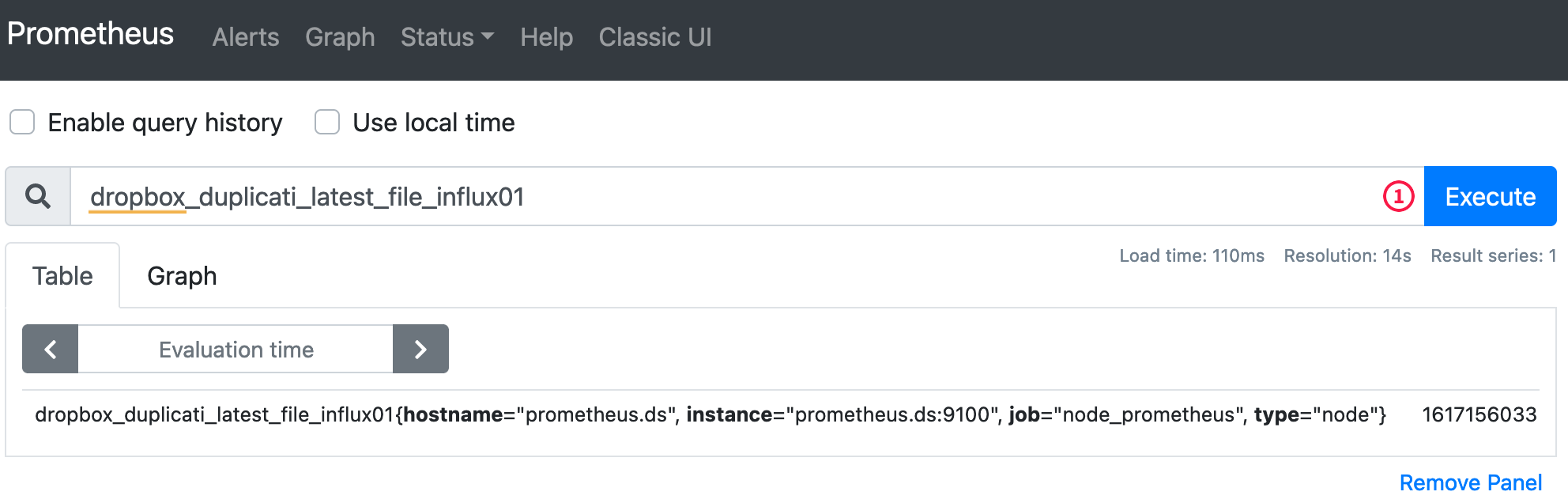
Drugi, Archer Connected Hosts Exporter, to narzędzie, dla którego wykonałem research zabezpieczeń mojego routera (opisany tu – https://blog.dsinf.net/2021/02/hacking-into-tp-link-archer-c6-shell-access-without-physical-disassembly/). Bada ono znane routerowi hosty i zwraca każdy znaleziony adres MAC jako osobny rekord Prometheusa z wartością binarną, na podstawie pliku z listą znanych adresów – 1 dla znanych i 0 dla nierozpoznanych urządzeń.
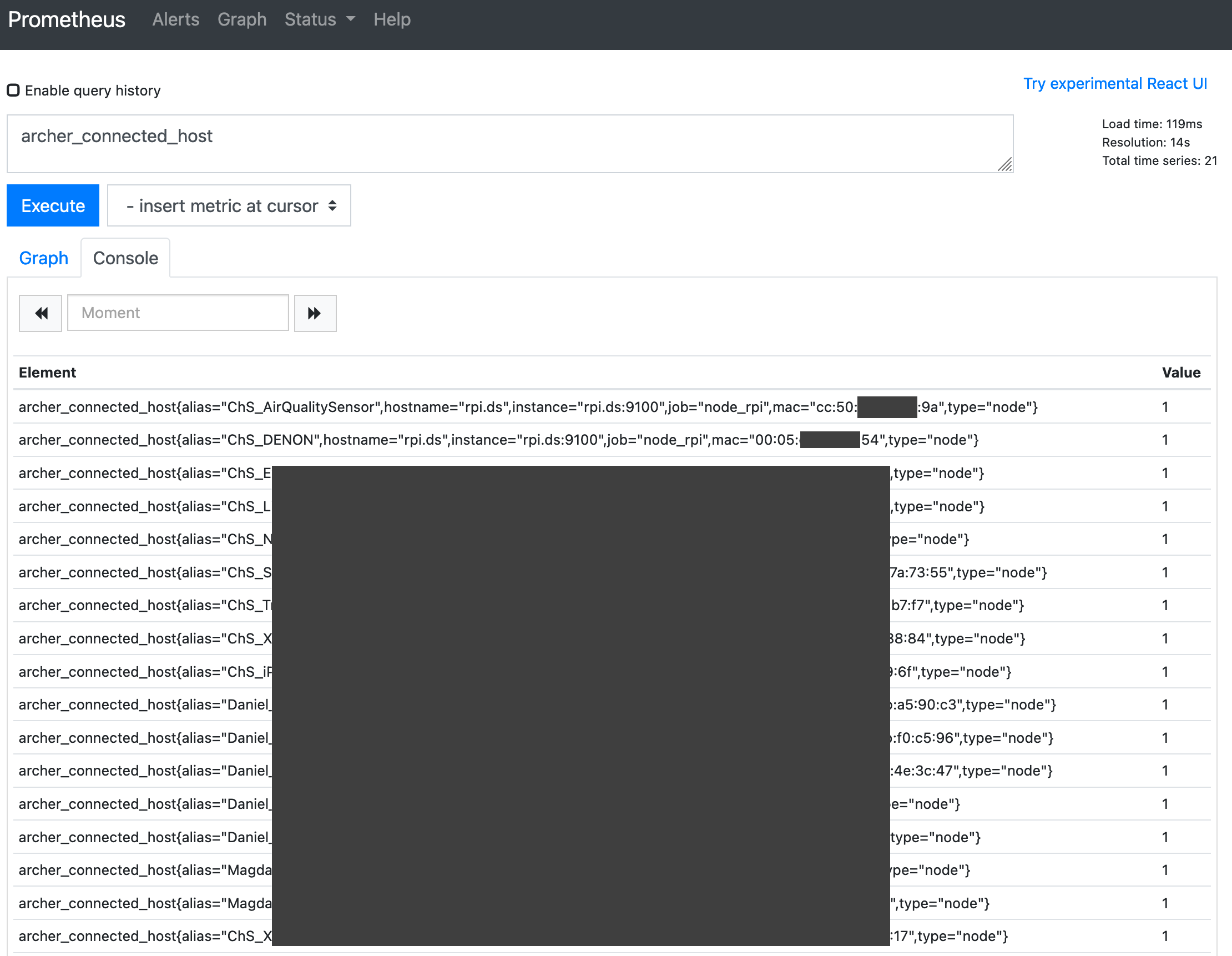
Oba narzędzia topornie, lecz pewnie uruchamia cron. W przypadku monitora routera co minutę zaś dla monitora Duplicati – raz dziennie, w momencie, kiedy backup powinien już dawno być zakończony.
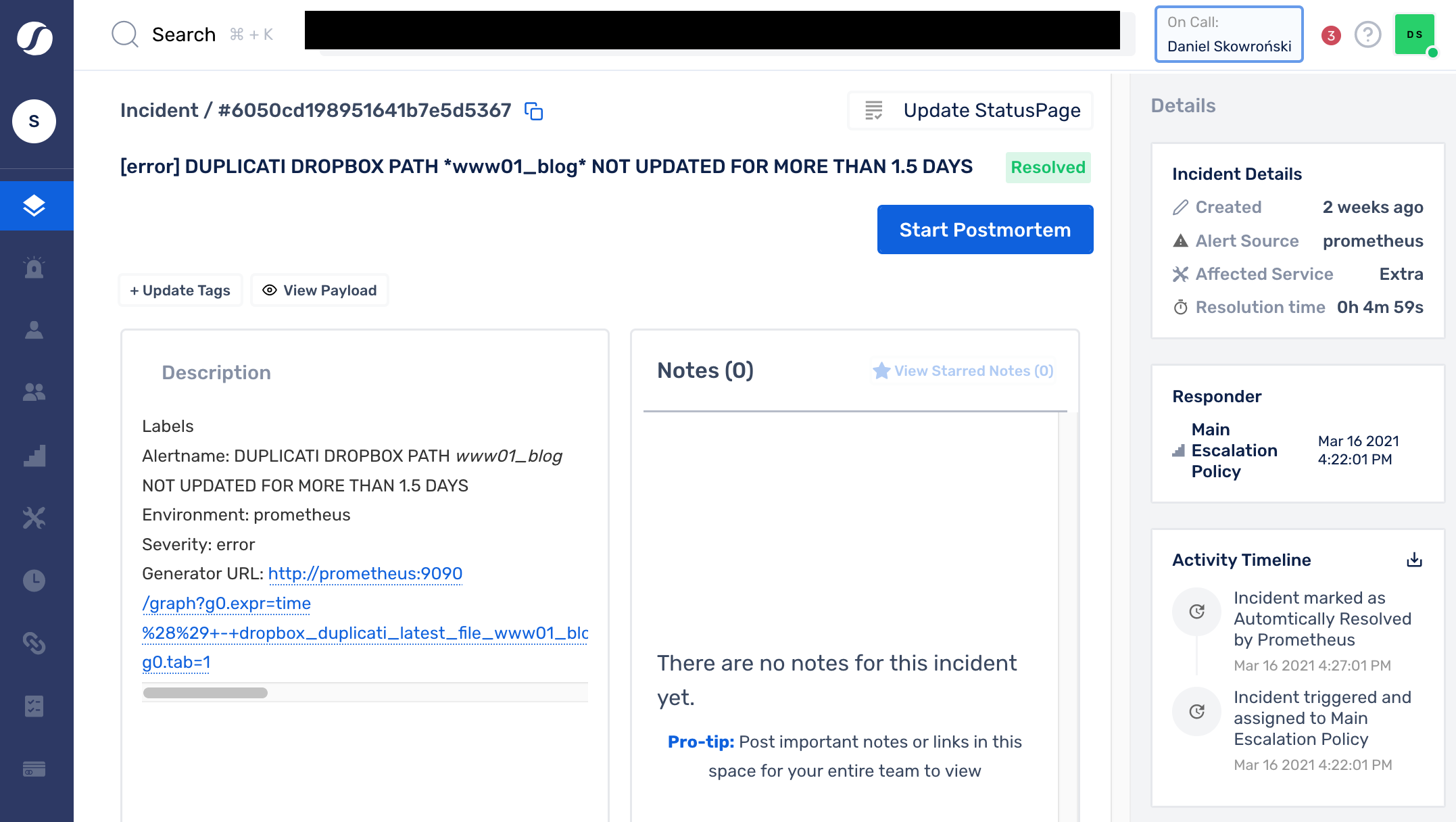
Alertowanie
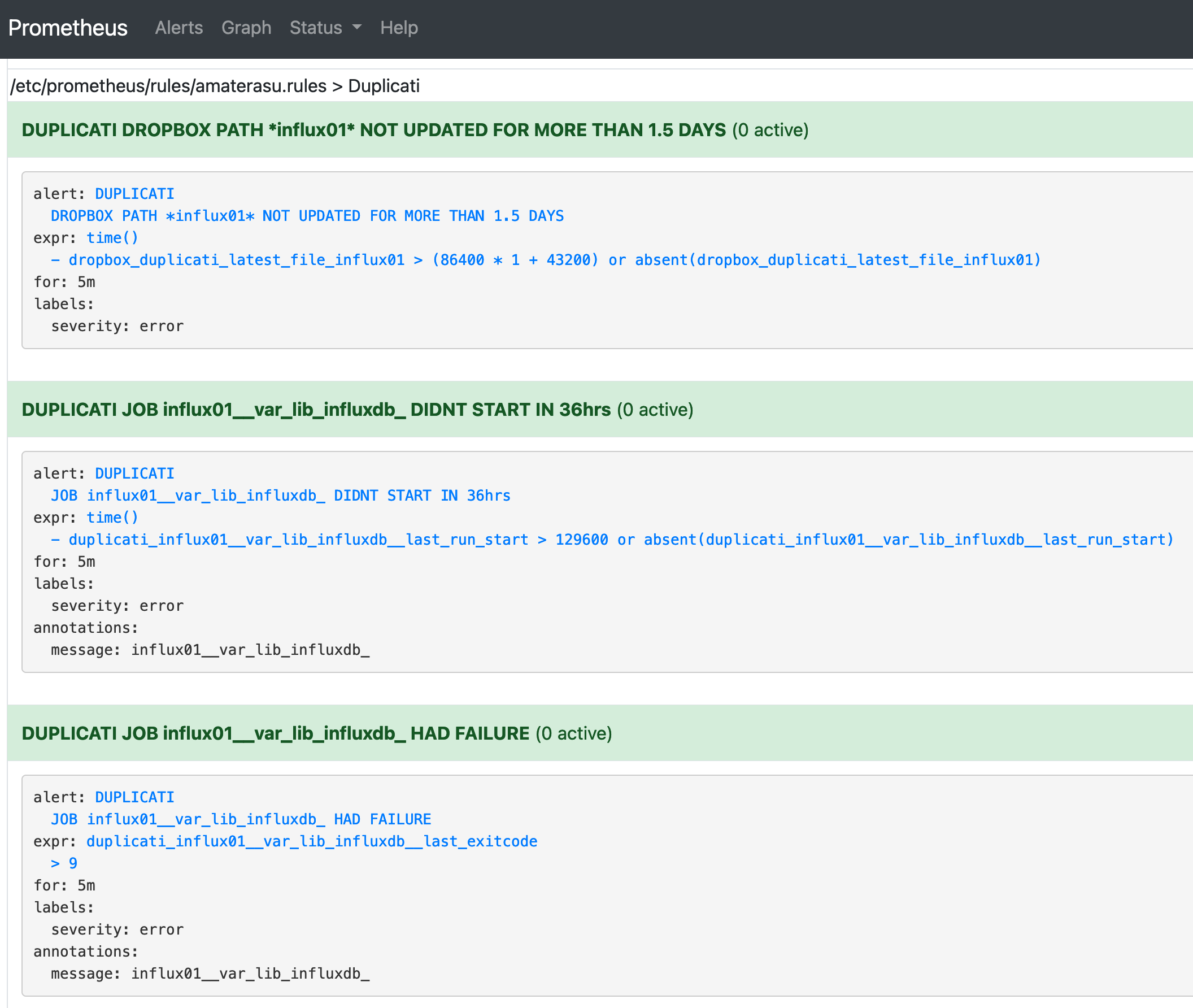
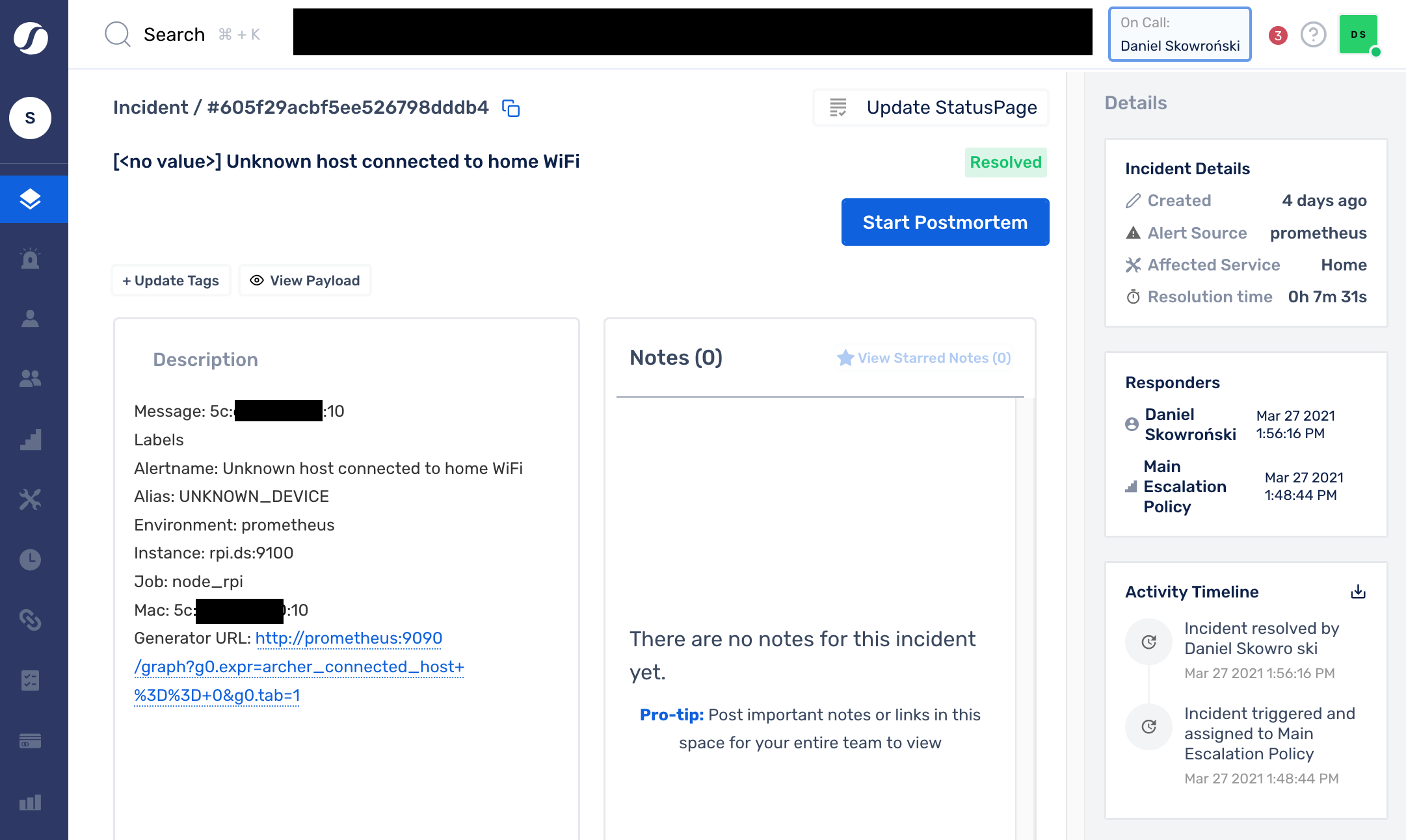
Oto jak prosto wyglądają definicje alertów w Prometheusie i przykładowe ich instancje w SquadCast:

Dlaczeni nie InfluxDB + Grafana?
Zamiast Prometheusa mógłbym używać na przykład wypychania danych do InfluxDB i alertowania używając Grafany (mając w zanadrzu te same miejsca do „wystrzelenia” alertów). Prometheus jednak dla mnie okazał się wygodniejszy w kwestii dynamicznego generowania definicji alertów za pomocą Ansible. Szczególnie że Grafana niestety dalej nie wspiera alertów dla metryk zawierających zmienne – co trochę zrozumiałe, ze względu na niejednoznaczność jak takie alerty miałyby działać. Skoro obejście to generowanie dashboardów Grafany za pomocą systemów szablonów, to prościej generować YAML dla Prometheusa, niż JSONa dla Grafany.
Tak wygląda fragment szablonu Jinja2 dla pliku rules.yml dla alert managera opisujący generowanie trójek alertów dla jednego backupowanego przez Duplicati miejsca:
- name: Duplicati
rules:
{% for dj in duplicati_monitored_jobs %}
- alert: DUPLICATI JOB {{dj.metric}} DIDNT START IN 36hrs
annotations:
message: '{{dj.metric}}'
expr:
time()-duplicati_{{dj.metric}}_last_run_start>129600
or
absent(duplicati_{{dj.metric}}_last_run_start)
for: 5m
labels:
severity: error
- alert: DUPLICATI JOB {{dj.metric}} HAD FAILURE
annotations:
message: '{{dj.metric}}'
description:
expr:
duplicati_{{dj.metric}}_last_exitcode>9
for: 5m
labels:
severity: error
{% endfor %}
{% for path in monitored_duplicati_dropbox_paths %}
- alert: DUPLICATI DROPBOX PATH *{{path.alias}}* NOT UPDATED FOR MORE THAN {{path.max_delay}}.5 DAYS
expr:
time()-dropbox_duplicati_latest_file_{{path.alias}}>(86400*{{path.max_delay}}+43200)
or
absent(dropbox_duplicati_latest_file_{{path.alias}})
for: 5m
labels:
severity: error
{% endfor %}
Podsumowanie
Także jak widać dołożenie nietypowych, skrojonych na konkretne potrzeby skryptów raportujących stan systemu lub inne metryki do Prometheusa, tak by wykorzystać jego system alertowania, jest banalnie proste skoro wystarczy zapisać do pliku tekstowego linijkę w rodzaju archer_connected_host{mac="12:34:56:78:90:ab",alias="friendly_alias"} 1, dodać prostą kwerendę do alert managera i mamy powiadomienia gotowe. Oczywiście, nie mając Prometheusa, pewnie prościej byłoby wykorzystać API komunikatora internetowego bezpośrednio, lecz jeśli już monitorujemy (a powinniśmy!) infrastrukturę, to jest to podejście prostsze i zgrabniejsze, a późniejsze korelowanie danych z kilku źródeł może być przydatne.